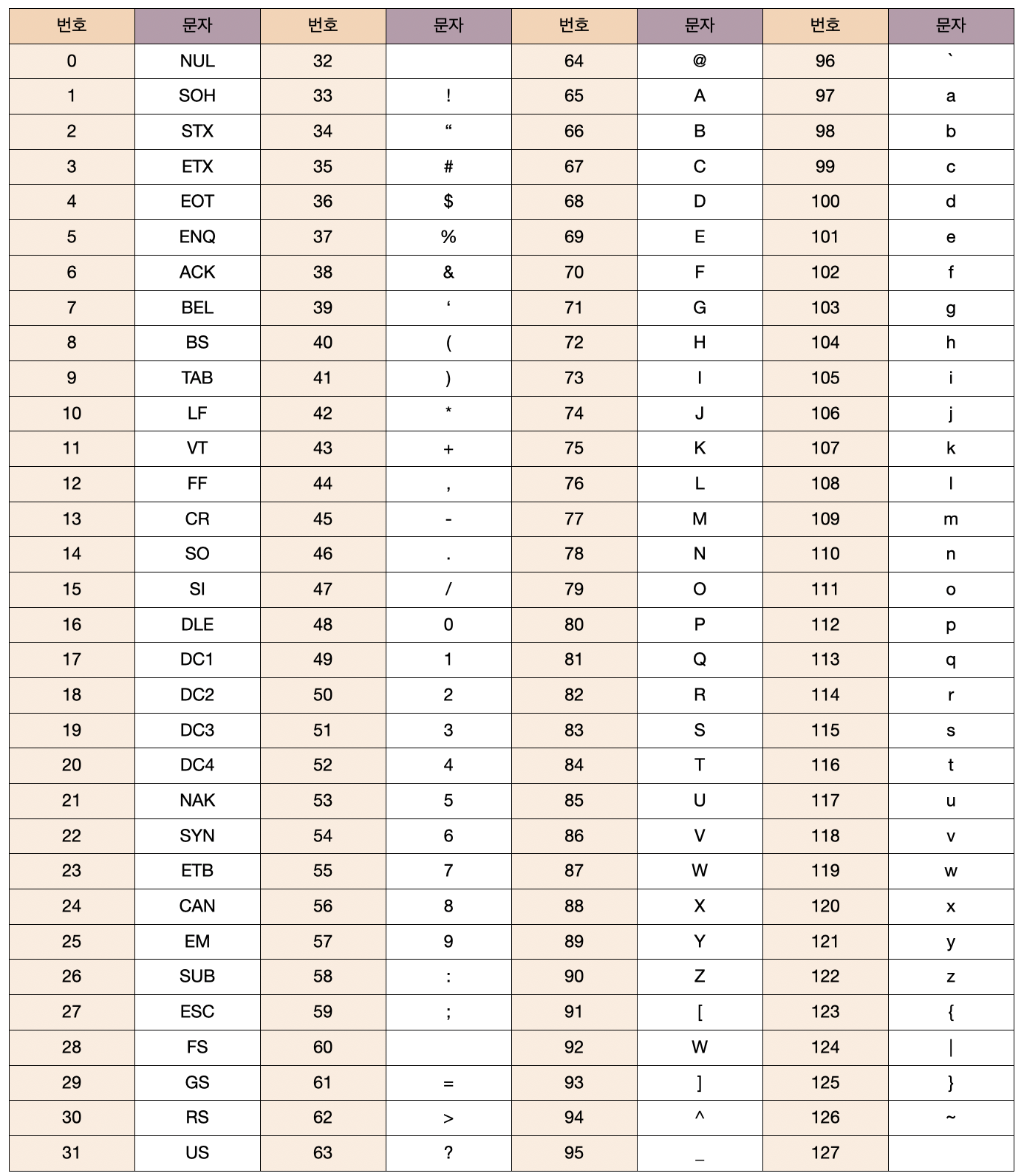
아스키 코드(ASCII)
아스키 코드는 128개의 문자 조합을 제공하는 7비트 부호로, 오류 검출을 위한 패리티 부호에 해당하는 1비트를 포함하여 총 8비트로 구성된다. 하나의 문자는 하나의 번호에 대응되며 문자 A를 숫자 65로 변환하는 것을 인코딩, 숫자 65를 해석하여 문자 A로 변환하는 것을 디코딩이라고 한다.
유니코드(Unicode)
아스키 코드는 미국의 표준이라 한국어, 일본어, 중국어 등의 외국어를 표현하는 데 한계가 있다. 그래서 전 세계 문자를 동일한 방법으로 표현하기위해 1995년 유니코드가 국제 표준으로 제정되었다.
1바이트를 사용하는 아스키 코드에 비해 유니코드는 2바이트(16비트)를 사용하므로 최대 수용할 수 있는 문자가 65,536개에 달한다. 아직 2만여 개는 새로 추가될 문자를 위해 남아있다고 한다.
초기엔 16비트였으나 표현할 문자나 이모티콘이 많아져 지금은 21비트로 늘렸다.
(U+0000 ~ U+10FFFF), (10FFFF은 10진법으로 약 111만)
유니코드 예시
비트를 4개씩 나눠서 16진법(4비트)으로 표현한다. 16진법을 사용하는 경우 맨 앞에 U+를 붙여 표시한다.
https://www.unicode.org/charts/PDF/UAC00.pdf
한편, 유니코드는 아스키 코드에 비해 사용하는 비트의 길이가 늘어나면서 처리 과정에서 비효율 문제가 발생했다.
그래서 UTF(unicode transformation format)은 문자코드의 길이를 가변적으로 변경하여 아스키 코드와 호환이 가능하도록 하여 이러한 문제를 보완했다.
UTF-8
유니코드에 대해 가변 길이 인코딩을 수행한다. 자주 쓰는 문자에 대해 1바이트로 처리하여 용량을 절약한다.
인코딩 결과는 1바이트~4바이트가 가능하며, 1바이트 문자는 아스키 코드와 호환된다. 예를 들어 'A'는 아스키코드의 65번으로, 인코딩 시 01000001로 표현되는데 이는 'A'를 UTF-8로 변환해도 동일하다.

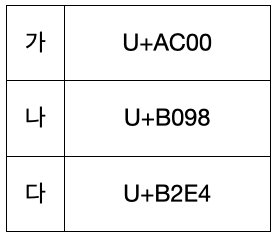
한글 '가'는 유니코드로 U+AC00이고
이는 0800~FFFF 구간에 해당되기 때문에 utf-8로 인코딩 시 3바이트로 저장된다.
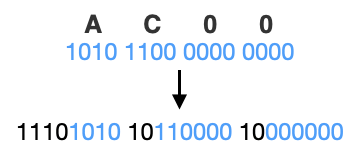
한편, 16진법의 AC00을 이진법으로 나타내면 1010 1100 0000 0000이기때문에
표에 표시된 x에 대응되게 되어 인코딩 결과는 11101010 10110000 10000000이 된다.





댓글